Paper reading: "Improve User Retention with Causal Learning"

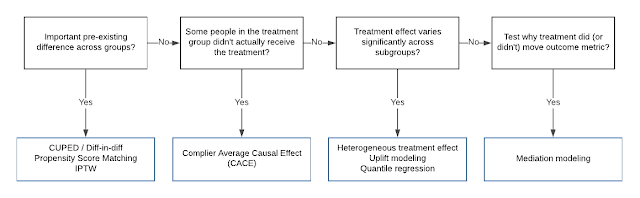
http://proceedings.mlr.press/v104/du19a/du19a.pdf Shuyang Du, James Lee, Farzin Ghaffarizadeh Here's the situation, handed to us in this paper from researchers at Uber: we'd like to offer a marketing promotion to our users in order to get them to retain better—to use our product more consistently over time. One way we can model this problem is with a binary random variable $Y^r$ (the $r$ stands for "retention"), where $Y_i^r = 1$ if and only if user $i$ used our product in a given time period. We could assume our marketing promotion has some fixed cost per user, then target the users with the highest treatment effect $\tau^r(x_i) = \mathbb{E}[Y_i^r(1) - Y_i^r(0) \mid X = x_i]$, where user $i$ has covariates $x_i$. This might be a valid framing for some marketing promotions. For others, it is incomplete. Let's say for example you run, I don't know, a ride-sharing company, maybe we can call you Uber. One promotion you might run is to offer everyone free r...